Crime prediction is a crucial application of machine learning, enabling law enforcement to make proactive decisions. This research presents a novel crime prediction model that leverages a hybrid approach by tuning the hyperparameters of Random Forest (RF) classifier using the Artificial Bee Colony (ABC) optimization algorithm. The model was developed to improve the prediction accuracy and reliability of crime prediction systems by enhancing the performance of traditional machine learning classifiers. To validate the effectiveness of the proposed RF-ABC model, a comparative analysis against Decision Trees (DT), k-Nearest Neighbors (KNN), and the existing untuned Random Forest model was conducted. Experimental results demonstrate that the proposed RF-ABC model significantly outperforms the baseline models across multiple performance metrics. Specifically, the RF-ABC achieved an accuracy of 95%, precision of 90%, recall of 93%, and an F1-score of 90%. In comparison, the existing RF model yielded an accuracy of 81%, precision of 87%, recall of 84%, and an F1-score of 83%, while DT and KNN models recorded notably lower scores. DT obtained a PEI of 0.6900, PAI of 0.669 and RRI of 0.5200, while KNN has a PEI of 0.9647, PAI of 0.8670 and RRI of 0.5267, RF-ABC had the best result. PEI of 0.9800, PAI of 0.9000 and RRI of 0.7200. Crime prediction metrics show that These findings confirm that the integration of ABC with RF not only fine-tunes the hyperparameters efficiently but also enhances the model's predictive capabilities. The proposed hybrid approach shows promising potential for real-world crime analytic and decision support systems in law enforcement.
| Published in | American Journal of Biological and Environmental Statistics (Volume 11, Issue 3) |
| DOI | 10.11648/j.ajbes.20251103.16 |
| Page(s) | 107-121 |
| Creative Commons |
This is an Open Access article, distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution and reproduction in any medium or format, provided the original work is properly cited. |
| Copyright |
Copyright © The Author(s), 2025. Published by Science Publishing Group |
Crime Prediction, Hyperparameter, Artificial Bee Colony (ABC), Random Forest
SN | Authors | Methods | Result obtained | Limitation |
|---|---|---|---|---|
1. | [14] | RF, DT and KNN algorithms were used. | RF outperform DT and KNN having 81% Accuracy | Over fitting, interpretability, data quality, high computational requirements, and performed only classification, |
2. | [15] | Random Forests, KNN and Kernel Density Estimation | RF greatly outperforms other crime prediction models. at micro places. | Interpretability, data quality, computational requirements, and ethical considerations |
3. | [2] | XGBoost machine learning method and SHAP method | It explores the integration of environmental factors, such as crime opportunity theory, routine activity theory, rational choice theory, and crime pattern theory, into crime prediction models | The trade-off between Interpretability and Transparency |
4. | [17] | Random Forest, Elastic Net, SVM | The study highlight the potential of ML models in identifying individuals at risk and devising proactive strategies to prevent criminal behavior among the population. | Refinement of risk prediction models is needed and variables with missing data were excluded from the analysis. |
5. | [18] | Na¨ıve Bayes (NB), K-Nearest Neighbour (KNN), Support Vector Machine (SVM), and Random Forest (RF). | The study accurately predict risks assessment it leverage a spatial and temporal data, and adapt to new information, handle large datasets and provide decision support. | Limited model accuracy when patterns of crime change over time |
6. | [5] | KNN, Decision tree, and Random forest | The study analyzed various factors and patterns which the model identify areas or individuals that are at higher risk of being involved in criminal activities. | Methods not Optimal |
Item | Description |
|---|---|
Name | Chicago crime |
Data Source | Chicago crime dataset |
Total Records | 239, 559 |
Total Columns | 24 |
Total Features | 23 |
Class | 5 |
Categorical Values | 5 |
Numerical Values | 19 |
Class Distribution | 6 |
Missing Values | 6,222 |
Year | 16-94 years |
Period | 12 Months |
S/n | Feature | Type | Full Name | Units |
|---|---|---|---|---|
1 | ID | Number | Identification Number | Number |
2 | Case Num | Categorical | Number of Case | Number |
3 | Date | Categorical | Date crime was committed | Date |
4 | Block | Categorical | Block crime was committed | Block |
5 | fUCR | Number | classification system | Classification |
6 | Prim Type | Categorical | Primary Type of crime | Type |
7 | Description | Categorical | Description of Crime | Description |
8 | Location | Categorical | Location crime was committed | Location |
9 | Gender | Categorical | Sex offender | Male/Female |
10 | Arrest | Categorical | Arrest was made | True/False |
11 | Domestic | Categorical | Domestic crime or not | True/False |
12 | Beat | Number | Geographic area | Location |
13 | District | Number | District crime was committed | District |
14 | Ward | Number | Ward crime was committed | Ward |
15 | Community | Number | community | Community |
16 | Crime Code | Categorical | code of crime | code |
17 | X Cord | Number | x coordinates | Degrees |
18 | Y Cord | Number | y coordinates | Degrees |
19 | Year | Categorical | Year of crime | 2022-2022 |
20 | Updated | Categorical | updated on database | Yes/No |
21 | Latitude | Number | Longitude | Degrees |
22 | Longitude | Number | Latitude | Degrees |
RF Parameters | Default | Minimum | Maximum |
|---|---|---|---|
NumTrees | 50 | 10 | 100 |
MaxNumSplits | 2 | 1 | 100 |
MinLeafSize | 1 | 1 | 5 |
MinParentSize | 10 | 5 | 20 |
Max Iteration | 100 | 10 | 1000 |
RF Parameters | Default |
|---|---|
Maximum Iteration | 100 |
Population of Bees | 50 |
Onlooker Bees | 50 |
Abandonment Limit | 0.6 |
Acceleration Coefficient | 1 |
RF Parameters | Existing | Optimal (Proposed RF-ABC) |
|---|---|---|
NumTrees | 50 | 70 |
MaxNumSplits | 2 | 4 |
MinLeafSize | 1 | 5 |
MinParentSize | 10 | 10 |
DT | KNN | Existing (RF) | Proposed (RF-ABC) | |
|---|---|---|---|---|
Accuracy | 74 | 79 | 81 | 95 |
Precision | 86 | 81 | 87 | 90 |
Recall | 68 | 70 | 84 | 93 |
F1-Score | 78 | 69 | 83 | 90 |
Parameter | DT | KNN | Existing (RF) | Proposed (RF -ABC) |
|---|---|---|---|---|
PEI | 0.69 | 0.7117 | 0.9647 | 0.98 |
PAI | 0.6617 | 0.6832 | 0.867 | 0.9 |
RRI | 0.52 | 0.5023 | 0.5267 | 0.72 |
DT | KNN | Existing (RF) | Proposed (RF-ABC) | |
|---|---|---|---|---|
Time (s) | 4 | 12 | 16 | 1291 |
Memory (kb) | 1.3 | 1.6 | 2.81 | 2.85 |
ABC | Artificial Bee Colony |
ARFF | Attribute Relationship File Format |
CSV | Command Separated Values |
DT | Decision Tree |
KNN | K - Nearest Neighbor |
LR | Linear Regression |
PAI | Predictive Accuracy Index |
PEI | Predictive Efficiency Index |
RRI | Recapture Rate Index |
RF | Random Forest |
SVM | Support Vector Machine |
| [1] | Adeyemi, R. A., Mayaki, J., Zewotir, T. T., & Ramroop, S. (2021). Demography and Crime: A Spatial analysis of geographical patterns and risk factors of Crimes in Nigeria. Spatial Statistics, 41, 100485. |
| [2] | Zhang, H., Gao, Y., Yao, D., & Zhang, J. (2023). Interaction of Crime Risk across Crime Types in Hotspot Areas. ISPRS International Journal of Geo-Information, 12(4), 176. |
| [3] | Bischl, B., Binder, M., Lang, M., Pielok, T., Richter, J., Coors, S., & Lindauer, M. (2023). Hyperparameter optimization: Foundations, algorithms, best practices, and open challenges. Wiley Interdisciplinary Reviews: Data Mining and Knowledge Discovery, 13(2), e1484. |
| [4] | Zhao, C., & Cao, H. (2022). Risk Evaluation of the Destination Port Logistics based on Self-Organizing Map Computing. In 2022 IEEE 22nd International Conference on Software Quality, Reliability, and Security Companion (QRS-C) (pp. 746-751). IEEE. |
| [5] | Ganesh, M. S. S., Sujith, M. B. R. P., Aravindh, K. V., & Durgadevi, P. (2023). Crime Prediction Using Machine Learning Algorithms. Advances in Science and Technology, 124, 457-461. |
| [6] | Plevris, V., Solorzano, G., Bakas, N. P., & Ben Seghier, M. E. A. (2022). Investigation of performance metrics in regression analysis and machine learning-based prediction models. In 8th European Congress on Computational Methods in Applied Sciences and Engineering (ECCOMAS Congress 2022). European Community on Computational Methods in Applied Sciences. |
| [7] | Yin, J. (2023). Crime Prediction Methods Based on Machine Learning: A Survey. Computers, Materials & Continua, 74(2). |
| [8] | Alsayadi, H. A., Khodadadi, N., & Kumar, S. (2022). Improving the regression of communities and crime using ensemble of machine learning models. J. Artif. Intell. Metaheuristics, 1(1), 27-34. |
| [9] | Campedelli, G. M. (2022). Machine Learning for Criminology and Crime Research: at the crossroads. Routledge. |
| [10] | Herzog, C. (2022). On the risk of confusing interpretability with explicability. AI and Ethics, 2(1), 219-225. |
| [11] | Ahamad, G. N., Shafiullah, Fatima, H., Imdadullah, Zakariya, S. M., Abbas, M., & Usman, M. (2023). Influence of optimal hyperparameters on the performance of machine learning algorithms for predicting heart disease. Processes, 11(3), 734. |
| [12] | Omotehinwa, T. O., & Oyewola, D. O. (2023). Hyperparameter optimization of ensemble models for spam email detection. Applied Sciences, 13(3), 1971. |
| [13] | Anyanwu, G. O., Nwakanma, C. I., Lee, J. M., & Kim, D. S. (2023). Novel hyper-tuned ensemble random forest algorithm for the detection of false basic safety messages in internet of vehicles. ICT Express, 9(1), 122-129. |
| [14] | Wubineh, B. Z. (2024). Crime analysis and prediction using machine-learning approach in the case of Hossana Police Commission. Security Journal, 1-16. |
| [15] | Wheeler, A. P., &Steenbeek, W. (2021). Mapping the risk terrain for crime using machine learning. Journal of Quantitative Criminology, 37, 445-480. |
| [16] | Liao, M., Wen, H., Yang, L., Wang, G., Xiang, X., & Liang, X. (2024). Improving the model robustness of flood hazard mapping based on hyperparameter optimization of random forest. Expert Systems with Applications, 241, 122682. |
| [17] | Watts, D., Moulden, H., Mamak, M., Upfold, C., Chaimowitz, G., & Kapczinski, F. (2021). Predicting offenses among individuals with psychiatric disorders-A machine learning approach. Journal of Psychiatric Research, 138, 146-154. |
| [18] | Rodrigues, A., González, J. A., & Mateu, J. (2023). A conditional machine learning classification approach for spatio-temporal risk assessment of crime data. Stochastic Environmental Research and Risk Assessment, 37(7), 2815-2828. |
| [19] | Abubakar, H., Boukari, S., Gital, A. Y., & Zambuk, F. U. (2024). A hyper-parameter tuned Random Forest algorithm-based on Artificial Bee Colony for improving accuracy, precision and interpretability of crime prediction. Dutse Journal of Pure and Applied Sciences, 10(4a), 371-381. |
| [20] | Adorada, A., Permatasari, R., Wirawan, P. W., Wibowo, A., &Sujiwo, A. (2018, October). Support vector machine-recursive feature elimination (svm-rfe) for selection of Micro RNA expression features of breast cancer. In 2018 2nd international conference on informatics and computational sciences (ICICoS) (pp. 1-4). IEEE. |
| [21] | Awad, M., &Fraihat, S. (2023). Recursive feature elimination with cross-validation with decision tree: Feature selection method for machine learning-based intrusion detection systems. Journal of Sensor and Actuator Networks, 12(5), 67. |
| [22] | Van Patten, I. T., McKeldin-Coner, J., & Cox, D. (2009). A microspatial analysis of robbery: Prospective hot spotting in a small city. Crime Mapping: A journal of research and practice, 1(1), 7-32. |
APA Style
Abubakar, H., Boukari, S., Gital, A. Y., Zambuk, F. U. (2025). Evaluation of a Hyperparameter Tuned Random Forest Algorithm Based on Artificial Bee Colony for Improving Accuracy and Precision of Crime Prediction Model. American Journal of Biological and Environmental Statistics, 11(3), 107-121. https://doi.org/10.11648/j.ajbes.20251103.16
ACS Style
Abubakar, H.; Boukari, S.; Gital, A. Y.; Zambuk, F. U. Evaluation of a Hyperparameter Tuned Random Forest Algorithm Based on Artificial Bee Colony for Improving Accuracy and Precision of Crime Prediction Model. Am. J. Biol. Environ. Stat. 2025, 11(3), 107-121. doi: 10.11648/j.ajbes.20251103.16
AMA Style
Abubakar H, Boukari S, Gital AY, Zambuk FU. Evaluation of a Hyperparameter Tuned Random Forest Algorithm Based on Artificial Bee Colony for Improving Accuracy and Precision of Crime Prediction Model. Am J Biol Environ Stat. 2025;11(3):107-121. doi: 10.11648/j.ajbes.20251103.16
@article{10.11648/j.ajbes.20251103.16,
author = {Hauwa Abubakar and Souley Boukari and Abdulsalam Ya’u Gital and Fatima Umar Zambuk},
title = {Evaluation of a Hyperparameter Tuned Random Forest Algorithm Based on Artificial Bee Colony for Improving Accuracy and Precision of Crime Prediction Model
},
journal = {American Journal of Biological and Environmental Statistics},
volume = {11},
number = {3},
pages = {107-121},
doi = {10.11648/j.ajbes.20251103.16},
url = {https://doi.org/10.11648/j.ajbes.20251103.16},
eprint = {https://article.sciencepublishinggroup.com/pdf/10.11648.j.ajbes.20251103.16},
abstract = {Crime prediction is a crucial application of machine learning, enabling law enforcement to make proactive decisions. This research presents a novel crime prediction model that leverages a hybrid approach by tuning the hyperparameters of Random Forest (RF) classifier using the Artificial Bee Colony (ABC) optimization algorithm. The model was developed to improve the prediction accuracy and reliability of crime prediction systems by enhancing the performance of traditional machine learning classifiers. To validate the effectiveness of the proposed RF-ABC model, a comparative analysis against Decision Trees (DT), k-Nearest Neighbors (KNN), and the existing untuned Random Forest model was conducted. Experimental results demonstrate that the proposed RF-ABC model significantly outperforms the baseline models across multiple performance metrics. Specifically, the RF-ABC achieved an accuracy of 95%, precision of 90%, recall of 93%, and an F1-score of 90%. In comparison, the existing RF model yielded an accuracy of 81%, precision of 87%, recall of 84%, and an F1-score of 83%, while DT and KNN models recorded notably lower scores. DT obtained a PEI of 0.6900, PAI of 0.669 and RRI of 0.5200, while KNN has a PEI of 0.9647, PAI of 0.8670 and RRI of 0.5267, RF-ABC had the best result. PEI of 0.9800, PAI of 0.9000 and RRI of 0.7200. Crime prediction metrics show that These findings confirm that the integration of ABC with RF not only fine-tunes the hyperparameters efficiently but also enhances the model's predictive capabilities. The proposed hybrid approach shows promising potential for real-world crime analytic and decision support systems in law enforcement.
},
year = {2025}
}
TY - JOUR T1 - Evaluation of a Hyperparameter Tuned Random Forest Algorithm Based on Artificial Bee Colony for Improving Accuracy and Precision of Crime Prediction Model AU - Hauwa Abubakar AU - Souley Boukari AU - Abdulsalam Ya’u Gital AU - Fatima Umar Zambuk Y1 - 2025/09/11 PY - 2025 N1 - https://doi.org/10.11648/j.ajbes.20251103.16 DO - 10.11648/j.ajbes.20251103.16 T2 - American Journal of Biological and Environmental Statistics JF - American Journal of Biological and Environmental Statistics JO - American Journal of Biological and Environmental Statistics SP - 107 EP - 121 PB - Science Publishing Group SN - 2471-979X UR - https://doi.org/10.11648/j.ajbes.20251103.16 AB - Crime prediction is a crucial application of machine learning, enabling law enforcement to make proactive decisions. This research presents a novel crime prediction model that leverages a hybrid approach by tuning the hyperparameters of Random Forest (RF) classifier using the Artificial Bee Colony (ABC) optimization algorithm. The model was developed to improve the prediction accuracy and reliability of crime prediction systems by enhancing the performance of traditional machine learning classifiers. To validate the effectiveness of the proposed RF-ABC model, a comparative analysis against Decision Trees (DT), k-Nearest Neighbors (KNN), and the existing untuned Random Forest model was conducted. Experimental results demonstrate that the proposed RF-ABC model significantly outperforms the baseline models across multiple performance metrics. Specifically, the RF-ABC achieved an accuracy of 95%, precision of 90%, recall of 93%, and an F1-score of 90%. In comparison, the existing RF model yielded an accuracy of 81%, precision of 87%, recall of 84%, and an F1-score of 83%, while DT and KNN models recorded notably lower scores. DT obtained a PEI of 0.6900, PAI of 0.669 and RRI of 0.5200, while KNN has a PEI of 0.9647, PAI of 0.8670 and RRI of 0.5267, RF-ABC had the best result. PEI of 0.9800, PAI of 0.9000 and RRI of 0.7200. Crime prediction metrics show that These findings confirm that the integration of ABC with RF not only fine-tunes the hyperparameters efficiently but also enhances the model's predictive capabilities. The proposed hybrid approach shows promising potential for real-world crime analytic and decision support systems in law enforcement. VL - 11 IS - 3 ER -
Computer Science Department, Abubakar Tafawa Balewa University Bauchi, Bauchi, Nigeria
Biography: Hauwa Abubakar is a PhD Student at Abubakar Tafawa Balewa University Bauchi (ATBU), Bauchi, Nigeria. She Obtained a Bachelor’s degree of Technology and a Master’s of Science in computer science from ATBU. She has attended a number of local and international Conferences in Nigeria. Her current research areas includes, Network security, machine learning, and cyber security

Computer Science Department, Abubakar Tafawa Balewa University Bauchi, Bauchi, Nigeria
Computer Science Department, Abubakar Tafawa Balewa University Bauchi, Bauchi, Nigeria
Biography: Abdulsalam Ya’u Gital is a Professor at Abubakar Tafawa Balewa University Bauchi (ATBU), Bauchi, Nigeria. He is currently involved in teaching, research and supervision of both undergraduate and Postgraduate students in computer science. he has a B-Tech, from ATBU, Bauchi Nigeria, M. Sc. and PhD in computer science from the University of Technology Malaysia (UTM). he serves as the Director of ICT and Deputy Dean of the Faculty of Science at ATBU. A professional member of several prestigious organizations. Professor Gital’s affiliations include the Association for Computing Machinery (ACM), IEEE computer society, Nigerian Computer Society (NCS), Computer Professional Registration Council of Nigeria (CPN) and Teachers without Borders African Regional chapter. His research interest encompasses, Deep Learning, Cloud Computing, Intelligent Systems and the Internet of Things (Io T). His work has been widely recognized in international referred journals and conferences highlighting his significant contributions to the field.

Computer Science Department, Abubakar Tafawa Balewa University Bauchi, Bauchi, Nigeria
Biography: Fatima Umar Zambuk is currently serving as the Head of the Department Computer Science, Faculty of Computing Abubakar Tafawa Balewa University Bauchi (ATBU), Bauchi, Nigeria. She Obtained a Bachelor’s Degree of Technology, a Master’s of Science and PhD in Computer Science from ATBU. She is currently involved in teaching and supervision of both Undergraduate and Postgraduate students of Computer Science from ATBU. Her current research areas includes, Cloud Computing, machine learning, and Optimization.

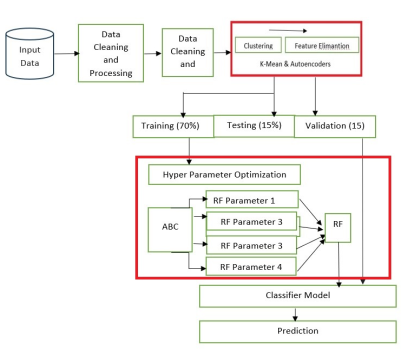
Figure 1. Architecture of the proposed RF- ABC (Source: [19]).
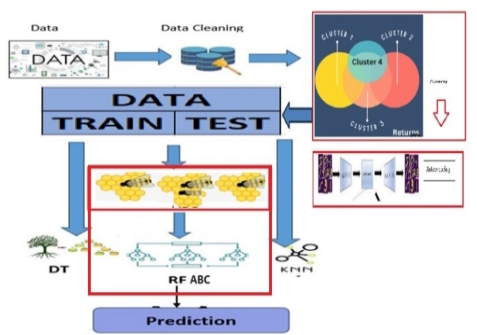
Figure 2. Framework of the proposed RF- ABC (Source: [19]).
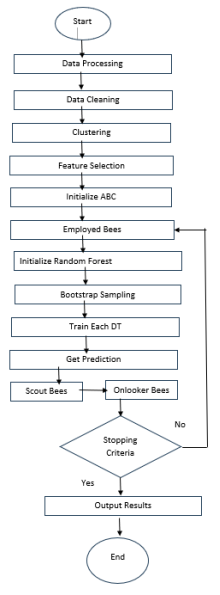
Figure 3. Flow Chart of the Proposed Model (Source: [19]).
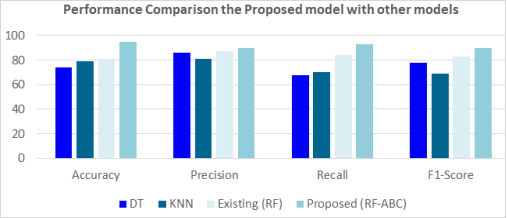
Figure 4. Performance comparison of the crime prediction models.
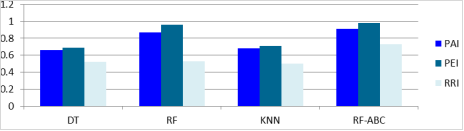
Figure 5. Performance comparison of the performance indices of the crime prediction models.
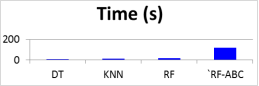
Figure 6. Graphical representation of Run Time of the crime prediction Models.
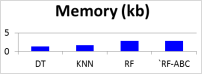
Figure 7. Graphical representation of Memory Used for the Models.
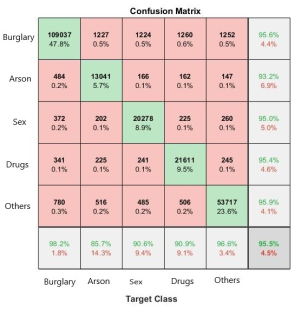
Figure 8. Confusion Matrix for predicted types using the RF-ABC crime prediction model.

